Story clustering: automatically group duplicate stories across your feeds
If you subscribe to more than a handful of news feeds, you’ve hit this problem: a story breaks, and suddenly the same headline appears across five, ten, twenty of your subscriptions. You’re reading the same article over and over, just published by different outlets. Your river view fills up with duplicates, and the stories you haven’t read yet get buried.
Story clustering solves this. When NewsBlur detects that multiple feeds are covering the same story, it groups them together and shows you the highest-scoring version. The duplicates don’t disappear – they fold neatly underneath, so you can still see who else reported it and jump to their version if you want a different perspective.
How it works
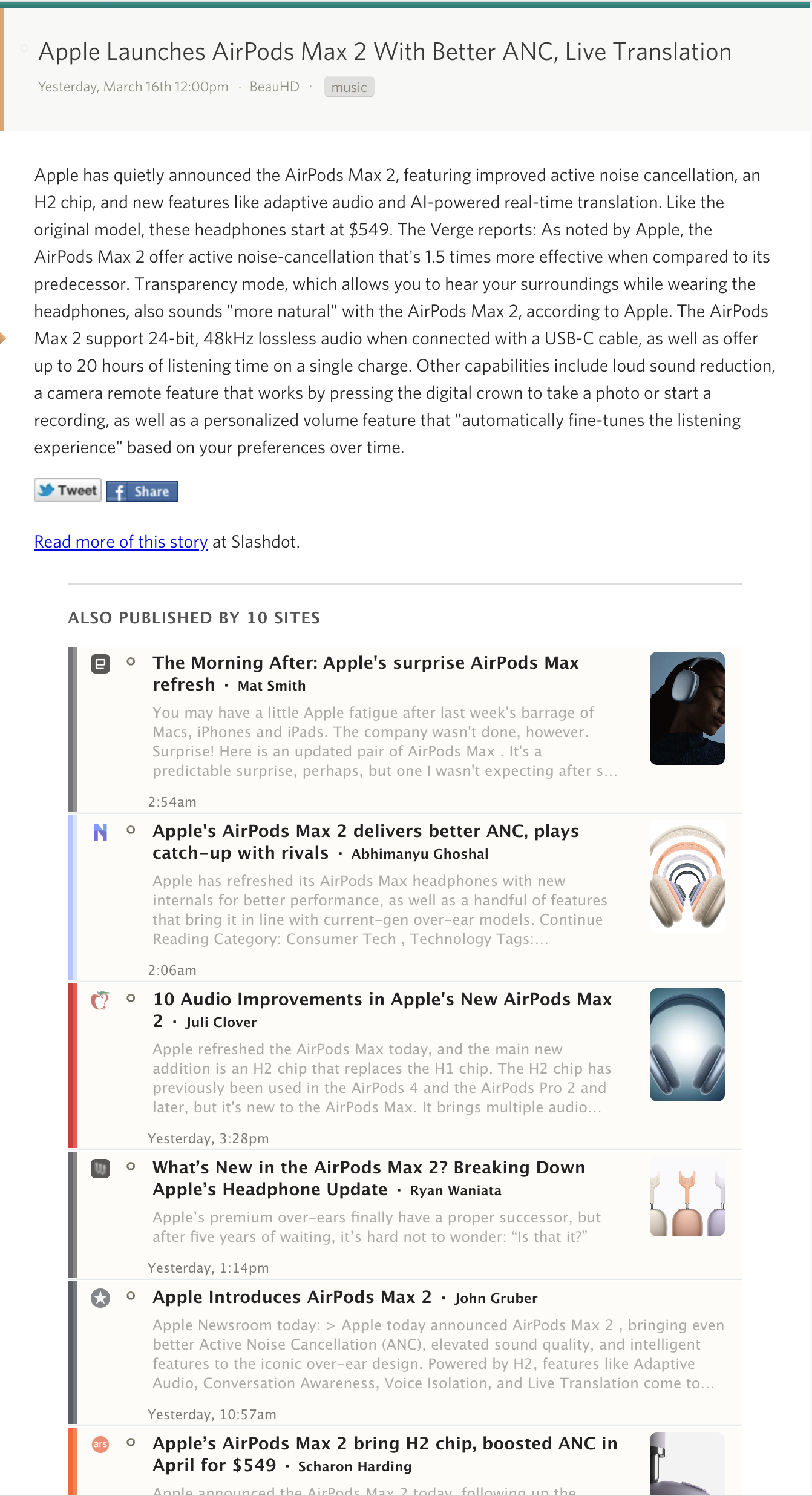
In the story titles list, clustered stories show their sources directly below the representative story. Each source shows the feed’s favicon, feed name, story title, and how long ago it was published. Click any source to read that version instead.

When you open a clustered story, the detail view shows rich cards for each alternative source at the bottom. These cards include the feed icon, story title, a content preview, the article’s thumbnail image, author, and date. Click any card to jump to that version of the story.
Two layers of detection
Clustering uses two complementary approaches to catch duplicates:
Title matching is the fast, obvious check. NewsBlur normalizes story titles (lowercasing, stripping punctuation) and groups exact matches. But it also does fuzzy matching using significant-word overlap – so “Apple Announces New iPhone” and “Apple Reveals the New iPhone at WWDC” will still cluster together, even though the titles aren’t identical.
Semantic matching goes deeper. NewsBlur sends each story’s title to Elasticsearch’s more_like_this query, searching across all your subscribed feeds for articles covering the same topic. This catches stories that are about the same event but written with completely different headlines. The two layers are merged, so title matches and semantic matches combine into a single cluster.
Clustering runs automatically in the background every time a feed updates. Results are cached for 14 days, so clusters are ready instantly when you load your river.
Mark duplicates as read
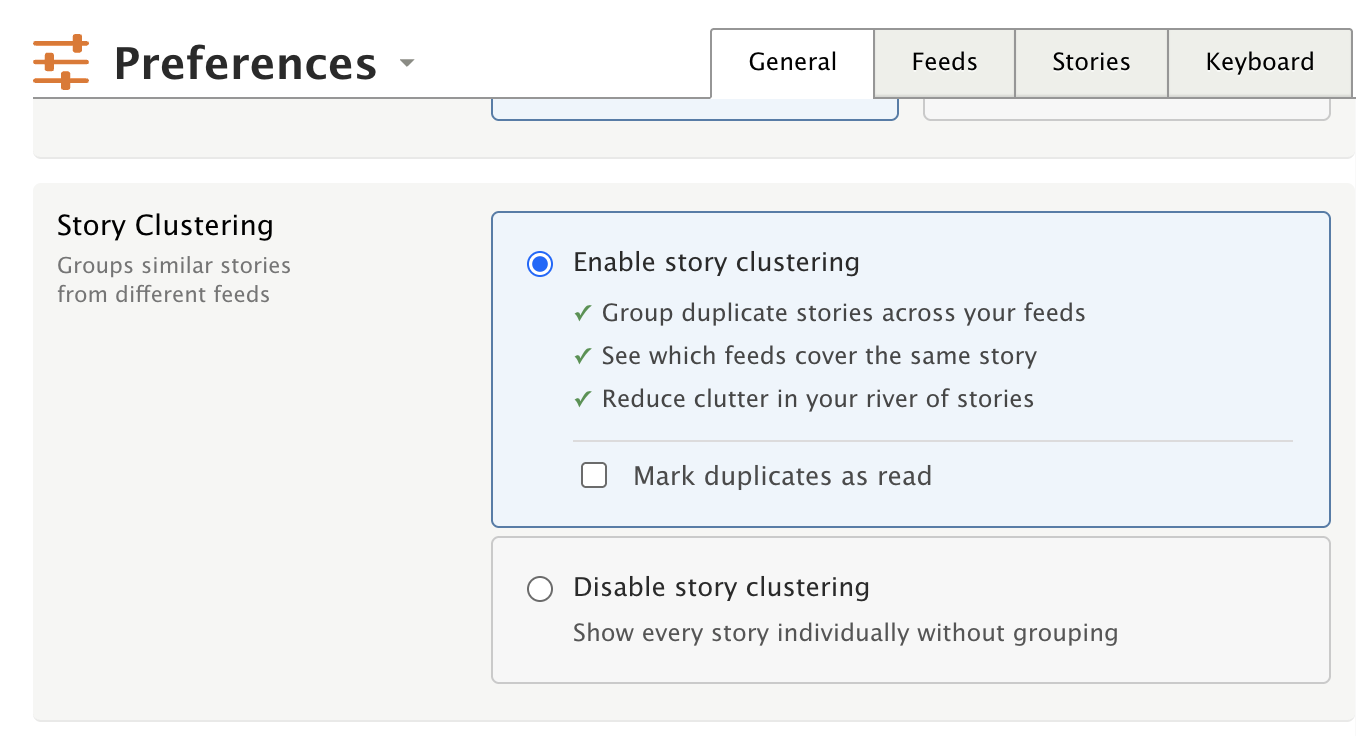
When you read a clustered story, you can optionally have NewsBlur mark all the duplicates as read too. This is off by default – enable it in the feed options popover under “Story Clustering” or in Manage > Preferences > Stories.
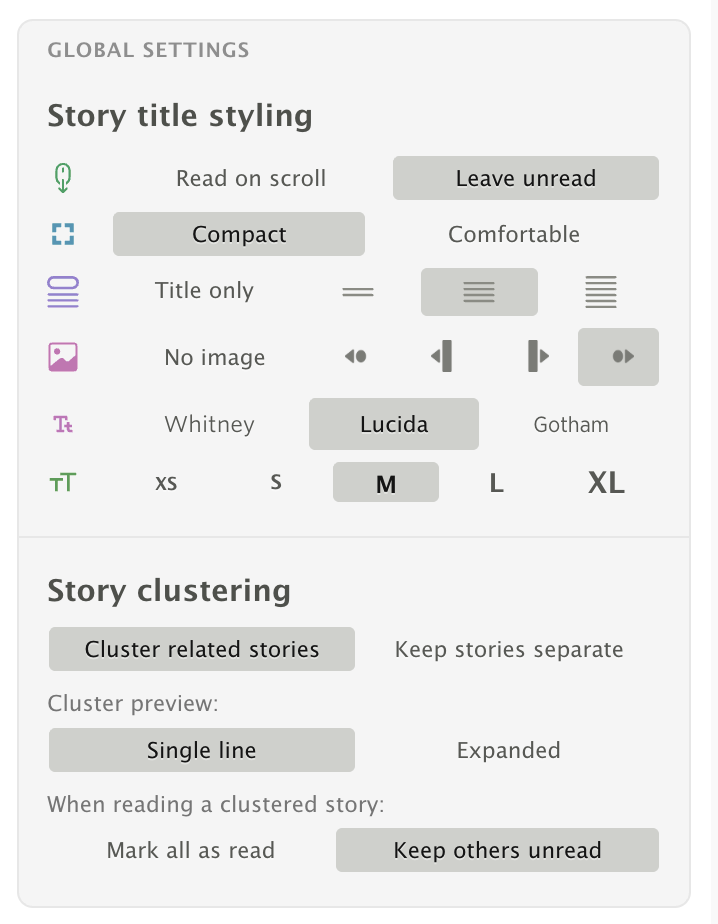
There are two controls:
- Cluster related stories / Keep stories separate – Toggles clustering on or off. When enabled, duplicate stories are grouped in your river view. When disabled, every story appears individually as before.
- Mark all as read / Keep others unread – When you read the representative story, this controls whether the other stories in the cluster are automatically marked as read.
The same options are available in the global Preferences dialog under the Stories tab.
Availability
Story clustering is available to all NewsBlur users on the web. If a feed you subscribe to has cluster data, you’ll see grouped stories automatically – no configuration needed. Clustering is now enabled by default for all users, and can be toggled off or back on in your account Preferences.
Premium Archive subscribers get full control over clustering: choose between single-line and expanded preview styles, and automatically mark duplicate stories as read when you read the representative story.
Premium and free users see clustered stories on popular feeds where cluster data already exists. You’ll see clusters most often on widely-subscribed news feeds. To unlock clustering settings and get clustering across all your feeds, upgrade to Premium Archive.
If you have feedback or ideas for improvements, please share them on the NewsBlur forum.